
MinIO in Maintenance Mode
What Operators Face Now – and Which Alternatives Are Truly Viable MinIO has put its Community …
04.12.2025
How to securely, efficiently, and cloud-natively provision GPU resources for development, inference, and training - including H100-MIG and Time-Slicing, YAML examples, and operational policies.
nvidia.com/mig-3g.40gb: 1), receive predictable performance, and only pay/consume what they use.This post shows end-to-end how to operate bare-metal Kubernetes (e.g., with NVIDIA H100) in a production-ready manner, how to effectively combine MIG and Time-Slicing, and which operational and governance aspects (quotas, labeling, monitoring, cost control) are crucial.
In short: Lower CAPEX/OPEX, increased productivity, controlled risk. No rocket science – just clean architecture.
A typical stack looks like this:
The central decision: MIG (hard isolation, fixed profiles) vs. Time-Slicing (cooperative sharing, very flexible) – or both, but cleanly separated per node.
MIG divides an H100 hardware-wise into isolated instances. Each instance receives a dedicated share of compute, L2 cache, HBM. Result: stable latency and no interference between tenants.
1g.10gb (each 10 GB)1g.20gb or 2g.20gb3g.40gb4g.40gb7g.80gb (full GPU)Rule of thumb: Performance scales roughly proportionally to the instance size. A
3g.40gbdelivers about 3/7 of the computing power of a full H100 (without the typical interference artifacts of soft-sharing).
# Enable MIG mode
nvidia-smi -mig 1
# Create MIG instances (Example: 3x 3g.40gb)
nvidia-smi mig -cgi 9,9,9 -C
# Display available profiles
nvidia-smi mig -lgipPractical Tips
The device plugin makes MIG profiles visible as discrete resources in the scheduler.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
template:
spec:
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.14.0
name: nvidia-device-plugin-ctr
env:
- name: MIG_STRATEGY
value: "single" # or "mixed"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-pluginsImportant
MIG_STRATEGY=single: Scheduler matches Pods against specific MIG profiles (nvidia.com/mig-3g.40gb).MIG_STRATEGY=mixed: More flexibility, but requires conscious resource definition and matching logic in the workloads.apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:12.0-base
resources:
limits:
nvidia.com/mig-3g.40gb: 1 # Requests a 3g.40gb MIG instanceIt’s that simple for developers: one line in resources.limits determines the size of the GPU slice.
Not optimal: Large-model training with strong GPU-to-GPU communication (NCCL, P2P). Here, a full GPU per Pod is more sensible – or multiple full GPUs per node/job.
Time-Slicing divides a GPU into time slots among multiple Pods. This increases utilization for workloads that do not constantly utilize the GPU (e.g., development notebooks, sporadic inference, pre-/post-processing).
apiVersion: v1
kind: ConfigMap
metadata:
name: gpu-sharing-config
namespace: kube-system
data:
config.yaml: |
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4 # Divides each GPU into 4 slots- env:
- name: CONFIG_FILE
value: /etc/kubernetes/gpu-sharing-config/config.yaml
volumeMounts:
- name: gpu-sharing-config
mountPath: /etc/kubernetes/gpu-sharing-configTrade-offs
Consistency beats micro-tuning. Plan your fleet in clear node roles:
**gpu-mig**: Nodes with active MIG and fixed profile layout (e.g., 3× 3g.40gb).**gpu-full**: Nodes with full GPUs (no MIG, no Time-Slicing) for training/HPC.**gpu-ts**: Nodes with Time-Slicing.kubectl label nodes gpu-node-1 gpu-type=h100-mig
kubectl label nodes gpu-node-2 gpu-type=h100-full
kubectl label nodes gpu-node-3 gpu-type=h100-tsWorkloads set node affinity or use separate node pools. Result: predictable scheduling, no side effects.
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: team-a
spec:
hard:
nvidia.com/mig-3g.40gb: "6"This prevents a team from “accidentally” occupying the entire cluster. In shared environments, also set LimitRanges and DefaultRequests.
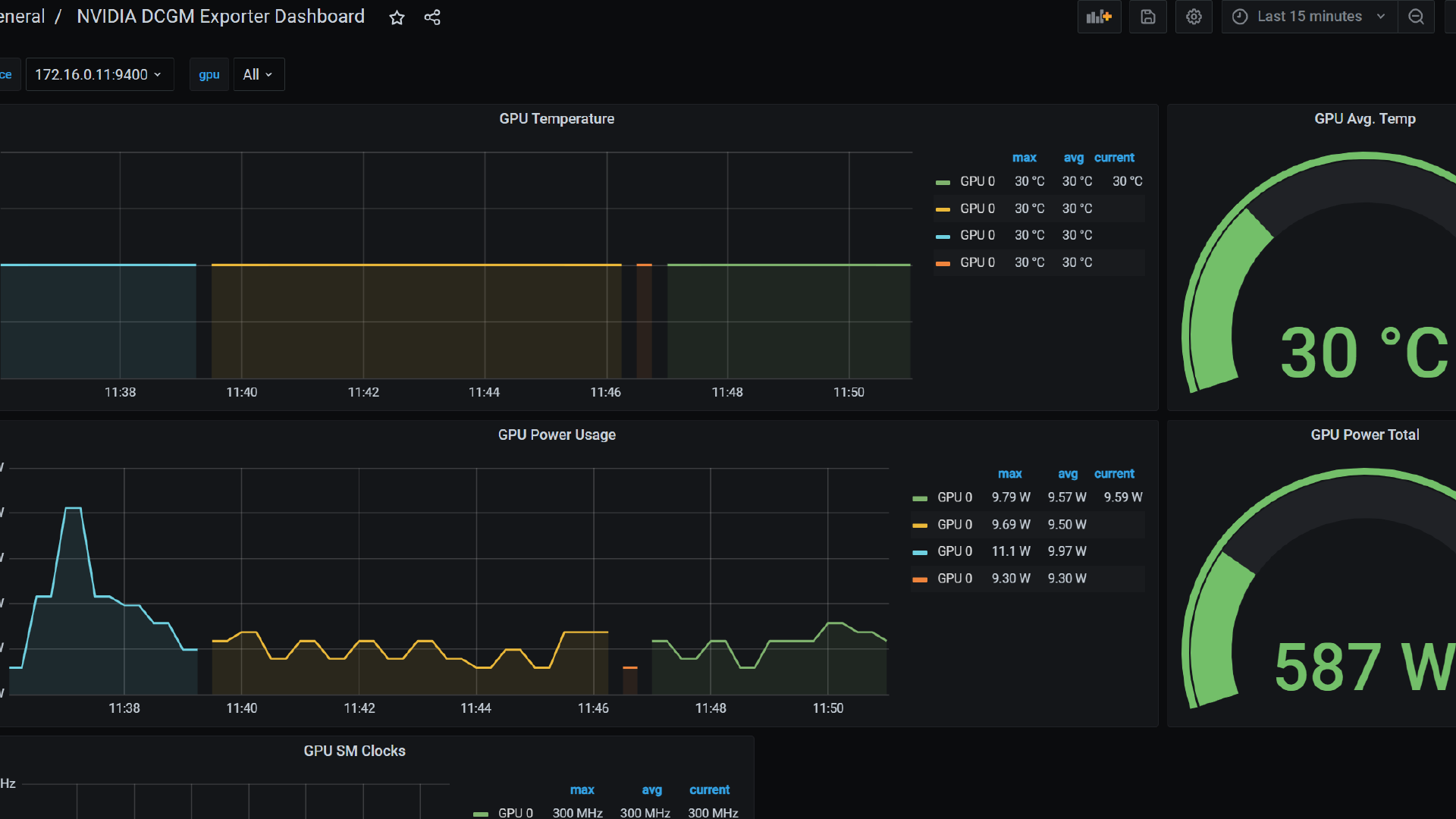
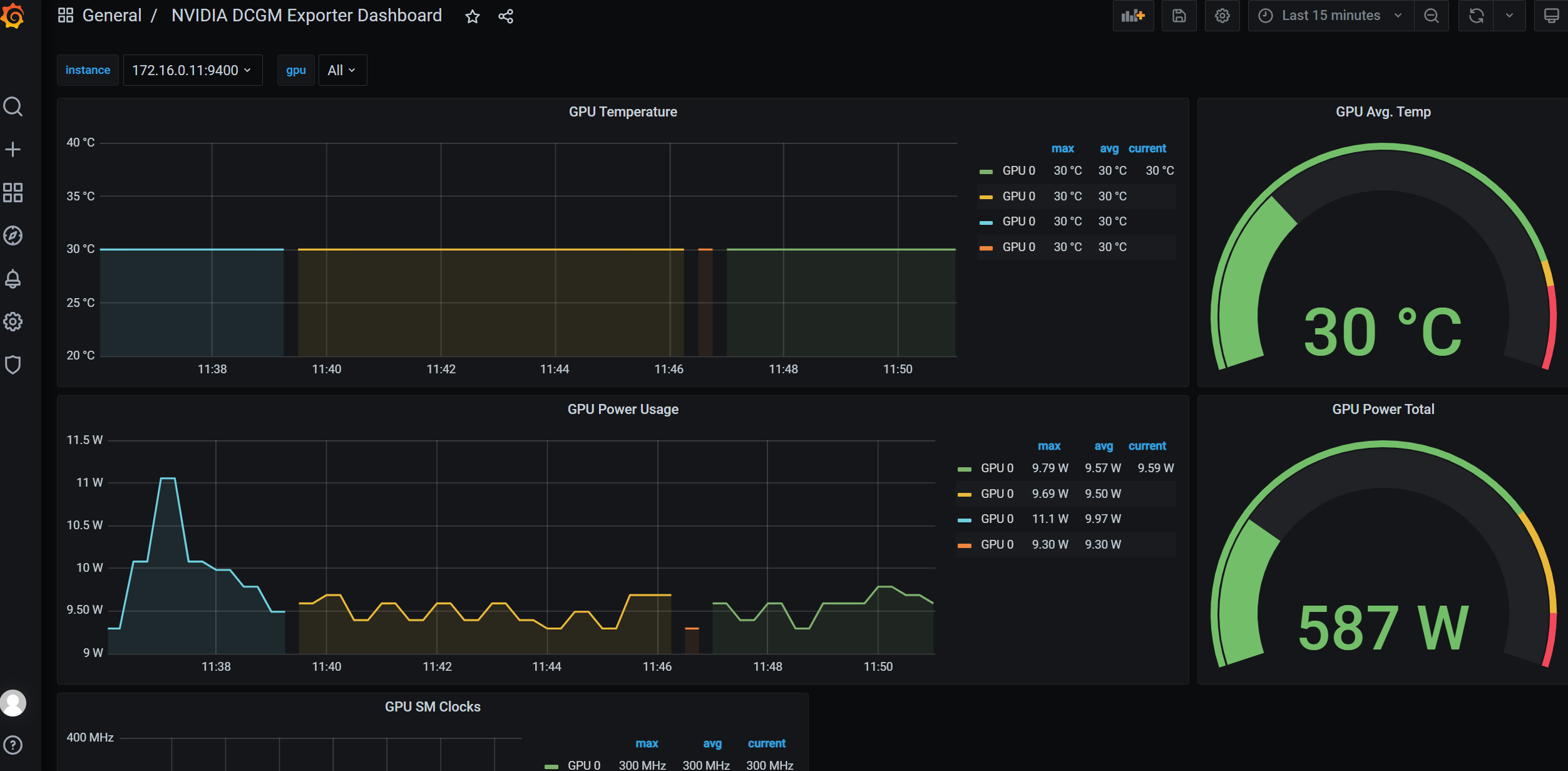
What you don’t measure, you can’t optimize. For GPUs, DCGM Exporter is the standard way to Prometheus/Grafana – including MIG awareness.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dcgm-exporter
spec:
template:
spec:
containers:
- name: dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.0.0
env:
- name: DCGM_EXPORTER_KUBERNETES_GPU_ID_TYPE
value: "mig-uuid"What to Monitor?
Target Image: A clear cost/utilization dashboard per namespace/team, tracked weekly. Utilization < 40%? Adjust profiles (coarser/finer), tune autoscaling, bundle training windows.
Developers want to simply request what they need – without tickets, without tribal knowledge.
limits: { nvidia.com/mig-<profile>: 1 }limits: { nvidia.com/gpu: 1 } (shared via ConfigMap)limits: { nvidia.com/gpu: 1 } on gpu-type=h100-fullnvcr.io/nvidia/cuda:<version>), plus PyTorch/TensorFlow variants.Change Management
GPU workloads in Kubernetes are powerful but sensitive to architectural details. To get the most out of an H100 fleet, you need to know and consciously adjust some levers.
In servers with multiple CPU sockets, GPUs are connected to specific NUMA nodes. If a Pod lands on the “wrong” NUMA node, additional PCIe hops occur, significantly degrading performance. For LLM inference, this is often still acceptable, but not for HPC or training jobs with high IO rates. Solution: Topology-aware scheduling.
What Operators Face Now – and Which Alternatives Are Truly Viable MinIO has put its Community …

Kubernetes SIG Network and the Security Response Committee have announced the official end for …

The rapid development of Artificial Intelligence, particularly Large Language Models (LLMs) like …