
Der Fall Localmind: Was passiert, wenn Sicherheitsversprechen nicht eingelöst werden
Der Fall Localmind: Was passiert, wenn Sicherheitsversprechen nicht eingelöst werden Die …
09.10.2025


Gerade redet jeder über KI, Large Language Models, Inference-Pipelines, Custom-LLMs und Co-Piloten für alle denkbaren Business-Prozesse. Was dabei gern vergessen wird: Die eigentliche Wertschöpfung entsteht nicht beim Prompt, sondern in der Infrastruktur, auf der die Modelle laufen.
Und genau hier wird es schnell unbequem.
Wer ernsthaft KI-Modelle für Enterprise-Prozesse betreiben will, landet ziemlich schnell bei zwei Fragen: Wo läuft das Modell? Und wer kontrolliert, wer darauf zugreift?
Viele fahren aktuell blind Richtung Public-Cloud-KI-Plattformen. Dort gibt es fertige APIs, hübsche Dashboards, automatisierte Training-Pipelines. Klingt bequem, skaliert schnell, wird aber teuer. Viel wichtiger: Die volle Kontrolle über das Modell, die Trainingsdaten, die Hyperparameter und die Inference-Pipelines bleibt beim Plattformanbieter.
Und noch kritischer: Die gesamte Betriebs- und Kontrolllogik läuft über Control Planes, die nicht unter eigener Jurisdiktion betrieben werden.
Für echte Enterprise-Integrationen mit sensiblen Daten (Kundendaten, Geschäftslogiken, internen Wissensbeständen, Finanzdaten, Dokumentationen) ist das keine Option.
KI wird produktiv erst dann spannend, wenn Modelle eng an eigene Datenräume gekoppelt werden — und zwar so, dass keine fremden Systeme im Kernprozess sitzen.
Deshalb braucht es eigene Infrastruktur, die nicht nur ein bisschen Compute bietet, sondern dedizierte GPU-Worker, Management-Systeme für LLM-Modelle, saubere API-Gateways und eine vollständige Integration in die bestehende Enterprise-IT.
GPU-Worker lokal, mit voller Kontrolle über Ressourcen, Scheduling, Inference-Loadbalancing und Training.
LLM-Management unter eigener Steuerung, ohne externe Vendor-Lock-ins.
Integrationen über bestehende interne Schnittstellen, nicht über fremde Plattform-APIs.
Policy-basiertes Security-Layering für Data Governance und Auditierbarkeit.
\
Genau das liefern wir mit unserer KI-Infrastruktur auf der Enterprise Cloud: souveräner KI-Betrieb auf eigener Hardware, aber vollständig orchestriert und automatisiert. Keine Bastellösung, kein abgespeckter Cloud-Ersatz, sondern produktiver KI-Betrieb als eigenständiger Baustein innerhalb der eigenen IT-Landschaft.
KI braucht Compute. Aber noch mehr braucht sie Kontrolle.
Wer heute noch kritische KI-Modelle in externe Plattformen verlagert, wird morgen erklären müssen, wem er welche Daten überlassen hat.
Die Infrastruktur entscheidet. Und die gehört dahin, wo die Verantwortung liegt: in die eigene Hand.
Der Fall Localmind: Was passiert, wenn Sicherheitsversprechen nicht eingelöst werden Die …
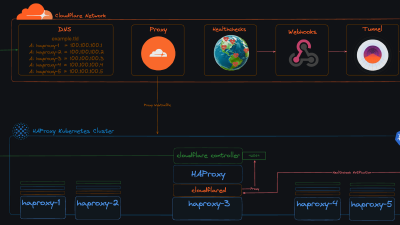
Cloudflare ist längst mehr als nur ein CDN-Anbieter. Neben Performance-Optimierung und …

Digitale Souveränität bezeichnet die Fähigkeit einer Organisation, ihre digitalen Systeme, …