
MinIO im Maintenance Mode
Was jetzt auf Betreiber zukommt – und welche Alternativen wirklich tragfähig sind MinIO hat seine …
04.12.2025
Wie du GPU‑Ressourcen sicher, effizient und cloud‑native für Entwicklung, Inferenz und Training bereitstellst – inklusive H100‑MIG und Time‑Slicing, YAML‑Beispielen und Betriebsrichtlinien.
nvidia.com/mig-3g.40gb: 1), erhalten planbare Performance und zahlen/verbrauch en nur, was sie nutzen.Dieser Beitrag zeigt End‑to‑End, wie man Bare‑Metal‑Kubernetes (z.B. mit NVIDIA H100) produktionsreif betreibt, wie man MIG und Time‑Slicing sinnvoll kombiniert und welche Betriebs‑ und Governance‑Aspekte (Quotas, Labeling, Monitoring, Kostenkontrolle) entscheidend sind.
Kurz: CAPEX/OPEX runter, Produktivität rauf, Risiko kontrolliert. Keine Raketenwissenschaft – nur saubere Architektur.
Ein typischer Stack sieht so aus:
Die zentrale Entscheidung: MIG (harte Isolation, feste Profile) vs. Time‑Slicing (kooperatives Teilen, sehr flexibel) – oder beides, aber knotenweise sauber getrennt.
MIG teilt eine H100 hardwareseitig in isolierte Instanzen. Jede Instanz erhält dedizierten Anteil an Compute, L2‑Cache, HBM. Ergebnis: stabile Latenz und keine Interferenz zwischen Tenants.
1g.10gb (je ~10 GB)1g.20gb oder 2g.20gb3g.40gb4g.40gb7g.80gb (volle GPU)Daumenregel: Performance skaliert grob proportional zur Instanzgröße. Eine
3g.40gbliefert etwa 3/7 der Rechenleistung einer vollen H100 (ohne die typischen Interferenz‑Artefakte von Soft‑Sharing).
# MIG-Modus aktivieren
nvidia-smi -mig 1
# MIG-Instanzen erstellen (Beispiel: 3x 3g.40gb)
nvidia-smi mig -cgi 9,9,9 -C
# Verfügbare Profile anzeigen
nvidia-smi mig -lgipPraxis‑Tipps
Das Device Plugin macht MIG‑Profile als discrete Ressourcen im Scheduler sichtbar.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
template:
spec:
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.14.0
name: nvidia-device-plugin-ctr
env:
- name: MIG_STRATEGY
value: "single" # oder "mixed"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-pluginsWichtig
MIG_STRATEGY=single: Scheduler matcht Pods gegen konkrete MIG‑Profile (nvidia.com/mig-3g.40gb).MIG_STRATEGY=mixed: Mehr Flexibilität, aber erfordert bewusste Ressourcen‑Definition und Matching‑Logik in den Workloads.apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvcr.io/nvidia/cuda:12.0-base
resources:
limits:
nvidia.com/mig-3g.40gb: 1 # Fordert eine 3g.40gb MIG-Instanz anSo simpel ist es für Developer: eine Zeile im resources.limits entscheidet über die Größe der GPU‑Scheibe.
Nicht optimal: Large‑Model‑Training mit starker GPU‑zu‑GPU‑Kommunikation (NCCL, P2P). Hier ist volle GPU pro Pod sinnvoller – oder mehrere volle GPUs per Node/Job.
Time‑Slicing teilt eine GPU in Zeitslots zwischen mehreren Pods. Das erhöht die Auslastung bei Workloads, die nicht ständig die GPU auslasten (z. B. Entwicklungs‑Notebooks, sporadische Inferenz, Pre‑/Post‑Processing).
apiVersion: v1
kind: ConfigMap
metadata:
name: gpu-sharing-config
namespace: kube-system
data:
config.yaml: |
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4 # Teilt jede GPU in 4 Slots- env:
- name: CONFIG_FILE
value: /etc/kubernetes/gpu-sharing-config/config.yaml
volumeMounts:
- name: gpu-sharing-config
mountPath: /etc/kubernetes/gpu-sharing-configTrade‑offs
Konsequenz schlägt Mikrotuning. Plane deine Flotte in klare Node‑Rollen:
**gpu-mig**: Nodes mit aktivem MIG und festem Profil‑Layout (z. B. 3× 3g.40gb).**gpu-full**: Nodes mit vollen GPUs (kein MIG, kein Time‑Slicing) für Training/HPC.**gpu-ts**: Nodes mit Time‑Slicing.kubectl label nodes gpu-node-1 gpu-type=h100-mig
kubectl label nodes gpu-node-2 gpu-type=h100-full
kubectl label nodes gpu-node-3 gpu-type=h100-tsWorkloads setzen Node Affinity oder nutzen separate NodePools. Ergebnis: Vorhersehbares Scheduling, keine seitlichen Effekte.
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: team-a
spec:
hard:
nvidia.com/mig-3g.40gb: "6"So verhinderst du, dass ein Team „aus Versehen" den ganzen Cluster belegt. In Shared‑Environments ergänzend LimitRanges und DefaultRequests setzen.
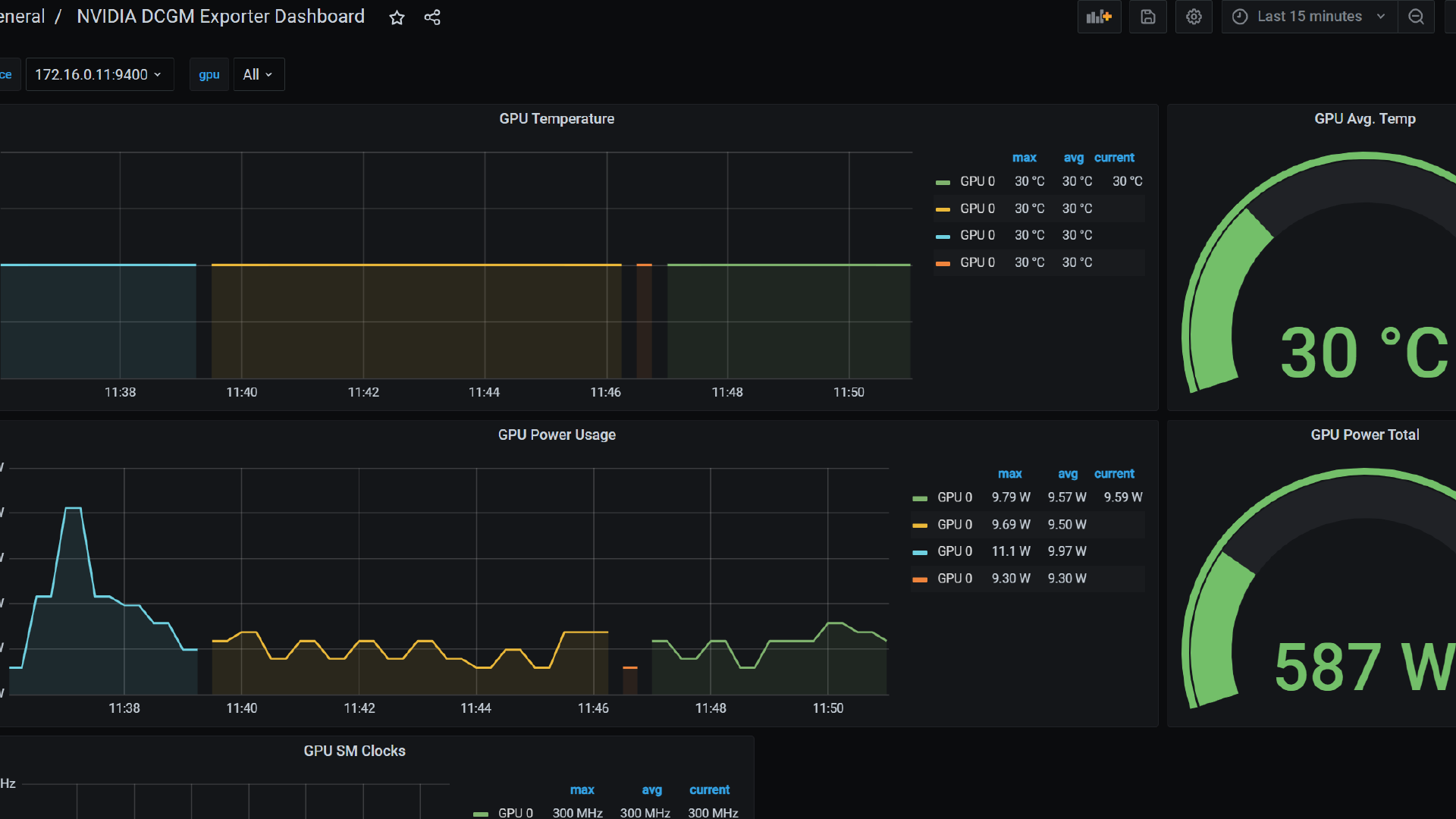
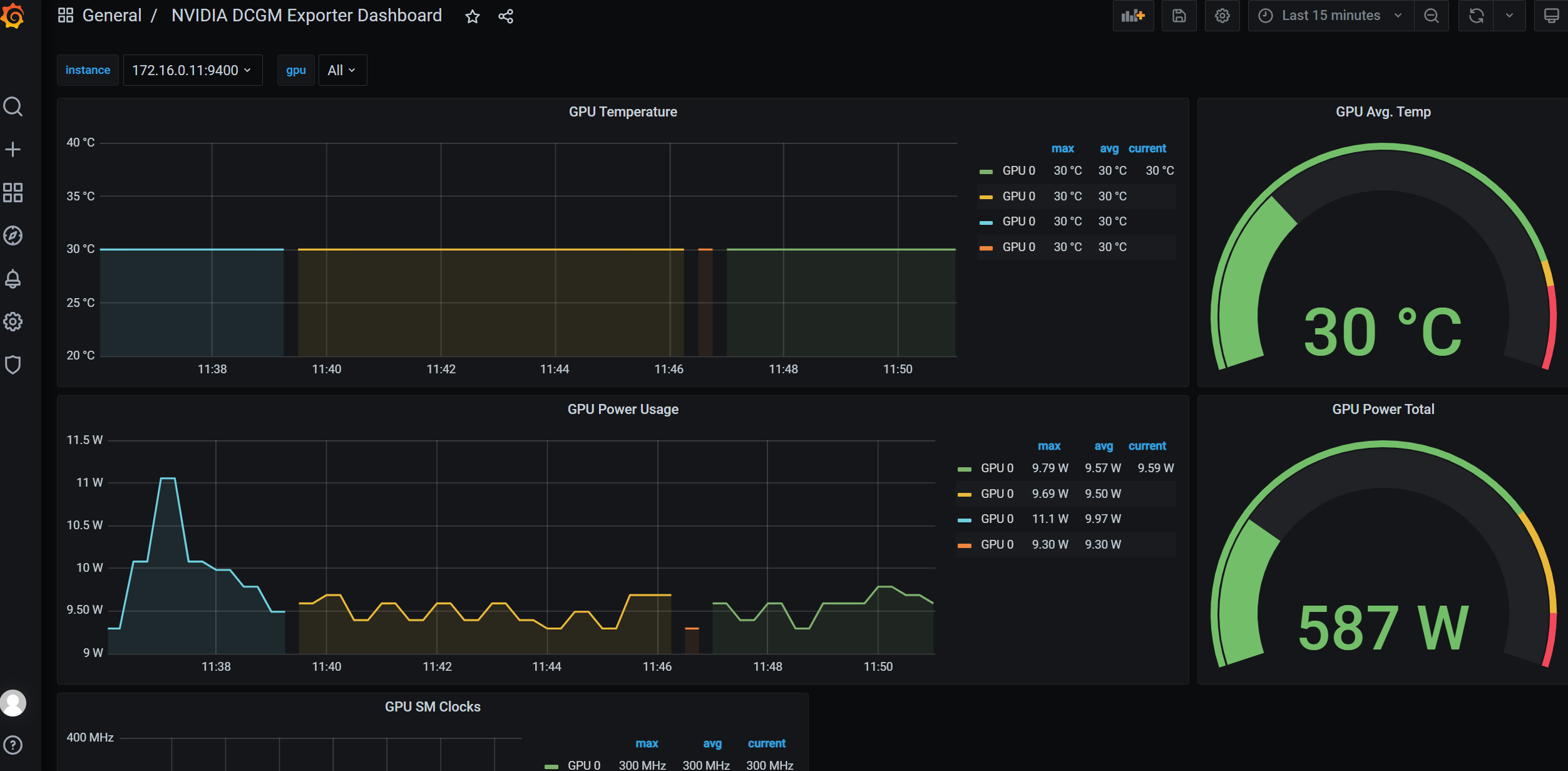
Was du nicht misst, optimierst du nicht. Für GPUs ist DCGM Exporter der Standardweg zu Prometheus/Grafana – inklusive MIG‑Awareness.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dcgm-exporter
spec:
template:
spec:
containers:
- name: dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.0.0
env:
- name: DCGM_EXPORTER_KUBERNETES_GPU_ID_TYPE
value: "mig-uuid"Was monitoren?
Zielbild: Ein klares Cost‑/Utilization‑Dashboard pro Namespace/Team, wöchentlich getrackt. Auslastung < 40 %? Profile anpassen (gröber/feiner), Autoscaling justieren, Trainingsfenster bündeln.
Entwickler wollen einfach anfordern, was sie brauchen – ohne Tickets, ohne tribal knowledge.
limits: { nvidia.com/mig-<profile>: 1 }limits: { nvidia.com/gpu: 1 } (geteilt per ConfigMap)limits: { nvidia.com/gpu: 1 } auf gpu-type=h100-fullnvcr.io/nvidia/cuda:<version>), plus PyTorch/TensorFlow Varianten.Change Management
GPU-Workloads in Kubernetes sind leistungsfähig, aber auch empfindlich gegenüber architektonischen Details. Wer das Optimum aus einer H100-Flotte herausholen will, muss einige Stellschrauben kennen und bewusst justieren.
In Servern mit mehreren CPU-Sockets hängen GPUs an spezifischen NUMA-Nodes. Wenn ein Pod auf dem „falschen" NUMA-Node landet, entstehen zusätzliche PCIe-Hops, die die Performance spürbar verschlechtern. Für LLM-Inference ist das oft noch akzeptabel, für HPC- oder Trainingsjobs mit hohen IO-Raten nicht. Lösung: Topology-Aware Scheduling aktivieren und den Kubernetes Topology Manager mit der Policy single-numa-node konfigurieren. Damit wird CPU-Affinity sichergestellt und unnötige Cross-Socket-Kommunikation vermieden.
MIG eignet sich hervorragend für Inferenz oder kleinere dedizierte Jobs – für verteiltes Training ist es dagegen ungeeignet. Frameworks wie PyTorch DDP oder Horovod setzen auf direkte GPU-zu-GPU-Kommunikation via NVLink oder InfiniBand. Diese ist bei MIG-Slices technisch nicht möglich. Wer also ernsthaftes Training betreiben möchte, sollte ganze GPUs pro Pod bereitstellen und MIG auf den betreffenden Nodes deaktivieren.
Time-Slicing ist ein nützliches Werkzeug, um GPUs mit mehreren Pods zu teilen. Aber zu viele Zeitscheiben pro GPU führen zu hohem Kontextwechsel-Overhead und schwankender Latenz. Als Faustregel gelten 2–4 Zeitscheiben für Development-Umgebungen (Notebooks, Testjobs) und maximal 6–8 für Produktionslasten. Die exakte Zahl hängt von den Workload-Charakteristiken ab: Batch-Verarbeitung verträgt mehr Replicas, latenzkritische Inferenz weniger.
Pods ohne GPU-Limits sind ein Planbarkeits-Killer. Kubernetes kann dann nicht sinnvoll schedulen und die Cluster-Auslastung wird unvorhersehbar. Best Practice: Erzwinge GPU-Limits per Admission Policy (z. B. OPA/Gatekeeper). Jeder Pod muss definieren, ob er einen MIG-Slice oder eine ganze GPU benötigt.
Das Device Plugin erlaubt mit MIG_STRATEGY=mixed das gleichzeitige Nutzen unterschiedlicher MIG-Profile. Klingt flexibel, ist aber komplex und nur sinnvoll, wenn die Organisation eine klare Standardisierung der Profile etabliert hat. Ohne klare Regeln führt es schnell zu Scheduling-Chaos und Ressourcenverschwendung.
GPU-Workloads sind empfindlich gegenüber Inkompatibilitäten in der CUDA/CUDNN/Treiber/Framework-Matrix. Versionen „frei flottieren" zu lassen, endet schnell in schwer reproduzierbaren Bugs. Empfehlung: Golden Images pro Workload-Familie pflegen, Versionen strikt pinnen und nur nach definierten Tests upgraden.
GPU-Jobs sind oft IO-gebunden. Selbst die schnellste H100 wartet sinnlos, wenn Daten zu langsam nachgeladen werden. Daher: NVMe-Storage lokal für Hotsets, Objektspeicher für große Datenmengen und Read-Only Volume Mounts für Modelle. Bei sehr großen Datenpipelines lohnt ein Blick auf RDMA-fähige Netzwerke.
Auch GPU-Workloads müssen Security-Best Practices einhalten. Container brauchen keine Root-Rechte, sondern sollten mit minimalen Capabilities, seccomp und AppArmor/SELinux-Profilen laufen. Filesysteme am besten read-only, wo möglich. Überraschend viele Beispiel-Manifeste im Netz arbeiten noch mit root-Containern – ein unnötiges Risiko.
Der wahre Kostenfaktor bei GPU-Clustern ist nicht die Anschaffung, sondern die unzureichende Auslastung. Eine H100, die im Schnitt nur zu 30 % ausgelastet ist, verbrennt Kapital. Ziel muss sein: durchschnittlich > 60 % Auslastung über die Woche hinweg.
MIG und Time-Slicing sind die zentralen Werkzeuge, um GPUs effizienter auszulasten. Statt eine volle GPU für einen kleinen Inferenz-Job zu blockieren, teilt man die Karte in mehrere Slices und erreicht so eine gleichmäßigere Verteilung.
Nicht jede Anwendung hat dieselben Anforderungen. Deshalb sollten GPU-Ressourcen in dedizierte Pools aufgeteilt werden:
So lassen sich Service Levels klar abgrenzen und unterschiedliche Preismodelle einfach erklären.
Kostentransparenz entsteht durch Metriken. Mit DCGM Exporter und Prometheus können GPU-Nutzungsdaten pro Namespace oder Pod erhoben werden. Daraus lassen sich Reports erstellen, die den Verbrauch klar darstellen („Team B verbrauchte 800 GPU-Stunden auf MIG-Slices"). Wer will, kann diese Daten in Chargeback-Modelle überführen – mit Preisen pro Slice oder Zeitslot. Das fördert Eigenverantwortung und reduziert interne Verteilungskämpfe.
In hybriden Szenarien lohnt es, unterschiedliche Kapazitätstypen zu nutzen:
Das senkt Kosten signifikant, ohne Verlässlichkeit zu gefährden.
Mit sauberem Slicing, klaren Pools und Kostentransparenz können mehr Teams und Jobs gleichzeitig auf derselben Hardware laufen. Anstelle von endlosen Diskussionen über GPU-Kontingente liefern Dashboards Fakten. Ergebnis: höhere Effizienz, weniger Politik, mehr Durchsatz.
nvidia-smi -mig 1
nvidia-smi mig -cgi 9,9,9 -C
nvidia-smi mig -lgipapiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
template:
spec:
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.14.0
name: nvidia-device-plugin-ctr
env:
- name: MIG_STRATEGY
value: "single"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-pluginskubectl label nodes gpu-node-1 gpu-type=h100-migapiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: team-a
spec:
hard:
nvidia.com/mig-3g.40gb: "6"apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dcgm-exporter
spec:
template:
spec:
containers:
- name: dcgm-exporter
image: nvcr.io/nvidia/k8s/dcgm-exporter:3.0.0
env:
- name: DCGM_EXPORTER_KUBERNETES_GPU_ID_TYPE
value: "mig-uuid"apiVersion: v1
kind: Pod
metadata:
name: inference-pod
namespace: team-a
spec:
nodeSelector:
gpu-type: h100-mig
containers:
- name: model-server
image: nvcr.io/nvidia/cuda:12.0-base
resources:
limits:
nvidia.com/mig-3g.40gb: 1
command: ["bash","-lc","nvidia-smi && python serve.py"]Ergebnis: Stabiler, isolierter Inferenz‑Pod auf einer dedizierten MIG‑Instanz mit sauberem Monitoring und Governance.
apiVersion: v1
kind: ConfigMap
metadata:
name: gpu-sharing-config
namespace: kube-system
data:
config.yaml: |
version: v1
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4- env:
- name: CONFIG_FILE
value: /etc/kubernetes/gpu-sharing-config/config.yaml
volumeMounts:
- name: gpu-sharing-config
mountPath: /etc/kubernetes/gpu-sharing-configkubectl label nodes gpu-node-3 gpu-type=h100-tsapiVersion: v1
kind: Pod
metadata:
name: dev-notebook
namespace: team-b
spec:
nodeSelector:
gpu-type: h100-ts
containers:
- name: notebook
image: nvcr.io/nvidia/cuda:12.0-base
resources:
limits:
nvidia.com/gpu: 1
command: ["bash","-lc","jupyter lab --ip=0.0.0.0 --no-browser"]Ergebnis: Vier Dev‑Pods teilen sich eine H100 kooperativ. Für notebooks ideal, für SLO‑kritische Produktion nicht
Die beschriebenen Methoden – MIG, Time-Slicing und klare Kubernetes-Integration – sind nicht nur auf High-End-On-Premises-Cluster mit Millionenbudget beschränkt. Gerade Anbieter wie Hetzner, die dedizierte GPU-Server ohne langfristige Vertragsbindung anbieten, eröffnen Unternehmen jeder Größe zusätzliche Handlungsoptionen.
Ein zentrales Problem vieler KI-Teams: Wie validieren wir unsere Modelle, ohne Produktionsressourcen zu blockieren?
Mit Hetzner lassen sich dedizierte GPU-Server flexibel und kurzfristig anmieten. Unternehmen können diese mit Kubernetes und dem NVIDIA Device Plugin ausstatten, MIG-Partitionen oder Time-Slicing konfigurieren und die gleiche Infrastruktur-Logik nutzen wie in ihrer On-Premises-Umgebung.
Vorteil: Entwickler können kostengünstig experimentieren, Benchmarks fahren oder Continuous-Integration-Pipelines für GPU-Workloads etablieren – ohne hohe Fixkosten oder langfristige Verpflichtungen.
In regulierten Branchen (z. B. Finance, Healthcare) ist es oft notwendig, neue Modelle in einer kontrollierten Umgebung zu verproben, bevor sie in produktive, streng überwachte Rechenzentren übernommen werden. Hetzner-Server sind dafür ideal:
Nicht jedes Unternehmen möchte oder darf sämtliche Workloads in die Public Cloud verlagern. Mit Hetzner entsteht ein kosteneffizienter Mittelweg:
Ein oft unterschätzter Vorteil von Anbietern wie Hetzner: Sie stellen rohe, dedizierte Hardware bereit, die vollständig in Kubernetes integriert werden kann – ohne proprietäre APIs oder Lock-in-Risiken.
Für Unternehmen bedeutet das:
Auch in streng regulierten Umfeldern bieten Hetzner-Server interessante Optionen. Zwar wird man hochkritische Workloads nicht in ein externes Rechenzentrum auslagern – aber für Development, Staging und Pre-Compliance-Tests reicht es oft, dass die Umgebung technisch mit der späteren Produktionsumgebung übereinstimmt. Mit Kubernetes-Namespace-Isolation, ResourceQuotas, RBAC und DCGM-Monitoring können auch bei externen GPU-Servern klare Governance-Mechanismen etabliert werden.
Die Kombination aus GPU-Slicing (MIG/TS), Kubernetes-Standardisierung und kostengünstigen Anbietern wie Hetzner erlaubt Unternehmen jeder Größe, flexibel zu arbeiten:
Ergebnis: Weniger Blockaden, schnellere Iteration, bessere Ressourcenauslastung – und das alles mit überschaubaren Kosten.
Als Managed Service Provider unterstützt ayedo Unternehmen dabei, GPU-Ressourcen in Kubernetes sicher, effizient und cloud-native bereitzustellen. Wir übernehmen die Implementierung von MIG-Layouts und Time-Slicing, richten dedizierte Node-Pools für Training, Inferenz und Development ein und sorgen mit Quotas, Monitoring und GitOps-Prozessen für Governance und Transparenz. Entwickler profitieren von standardisierten Workflows und Self-Service-Mechanismen, während Entscheider die volle Kontrolle über Kosten, Auslastung und Compliance behalten. So entsteht eine zukunftsfähige GPU-Infrastruktur, die Innovation beschleunigt und zugleich Ressourcen optimal nutzt.
Was jetzt auf Betreiber zukommt – und welche Alternativen wirklich tragfähig sind MinIO hat seine …

Kubernetes kündigt das Ende von Ingress NGINX an Kubernetes SIG Network und das Security Response …

Die rasante Entwicklung von Künstlicher Intelligenz, insbesondere von Large Language Models (LLMs) …